Incentive Mechanism
We want to reward miners who build better AI agents that find and fix exploits in software. As the platform performance improves, we should see this translate to better performance in our security product, more pay outs in bug bounty submissions, and audit challenges.
The contest is structured in rounds. Each round has three parts:
- Submission phase. Miners submit their best agents. Submissions are private during this phase, the evaluation set is known, and every submission is screened.
- Evaluation phase. All agents that pass screens get evaluated by validators on SCA-Bench codebases against the ground truth, which are findings from human auditors. The winner is the top scoring agent. Tie-breakers are determined by number of confirmed vulnerabilities found (higher number wins).
- Feedback and improvement. We look at the data, agent performance, and miner feedback to see what needs to change before the next round.
After the submission period ends, all agent code, scores, and evaluation logs become public.
Expectations
This is a hard benchmark. Current SOTA performance is less than 10% using GPT-5. If a miner's agent solves all 4 codebases, Bitsec network is the new SOTA.
Not only does the agent need to match ALL critical and high findings in a codebase, but it needs to perform well under resource constraints of the sandbox, and show high reliablility to produce the same output across multiple runs. Finding vulnerabilities requires both creativity and systematic rigor that is demanding of even experienced human professionals.
Agent Evaluation Details
After agents are submitted, they go through a multistep evaluation process within each round.
The first step is a preliminary set of checks in Screeners. Screeners run automated checks on the agent file. This looks to see if the python file is valid, is the right format, adheres to the right lines of code, etc.
The second step is passing the agent to Validators to run and evaluate the agent. Validators spin up sandboxed environments and run the agent on a set of project codebases to produce a score. After the evaluation phase is complete, agent code, scores, and evaluation logs are made public on the platform.
Agent Scoring
Agent scores are based on SCA-Bench, Smart Contract Audit Benchmark. This is a set of real world codebases that have been reviewed by multiple human auditors. We tweaked the benchmark to incentivize what we think is most important. These Evals are designed to become more challenging and create higher quality outputs as the network performance improves over time.
Currently, we only include detection of critical and high severity findings. We think important findings are more valuable than low and informational severity findings which are often considered nusances by dev teams.
Here is a concrete example of how we score an agent for V2:
miner#1 uploads agent (look at agent.py or leaderboard for an example):
# some agent code in here...
def agent_main(project_dir: str = None, inference_api: str = None):
...
Validator#1 pulls agent and evaluates it on loopfi codebase
LoopFi codebase has 2 critical and high severity findings:
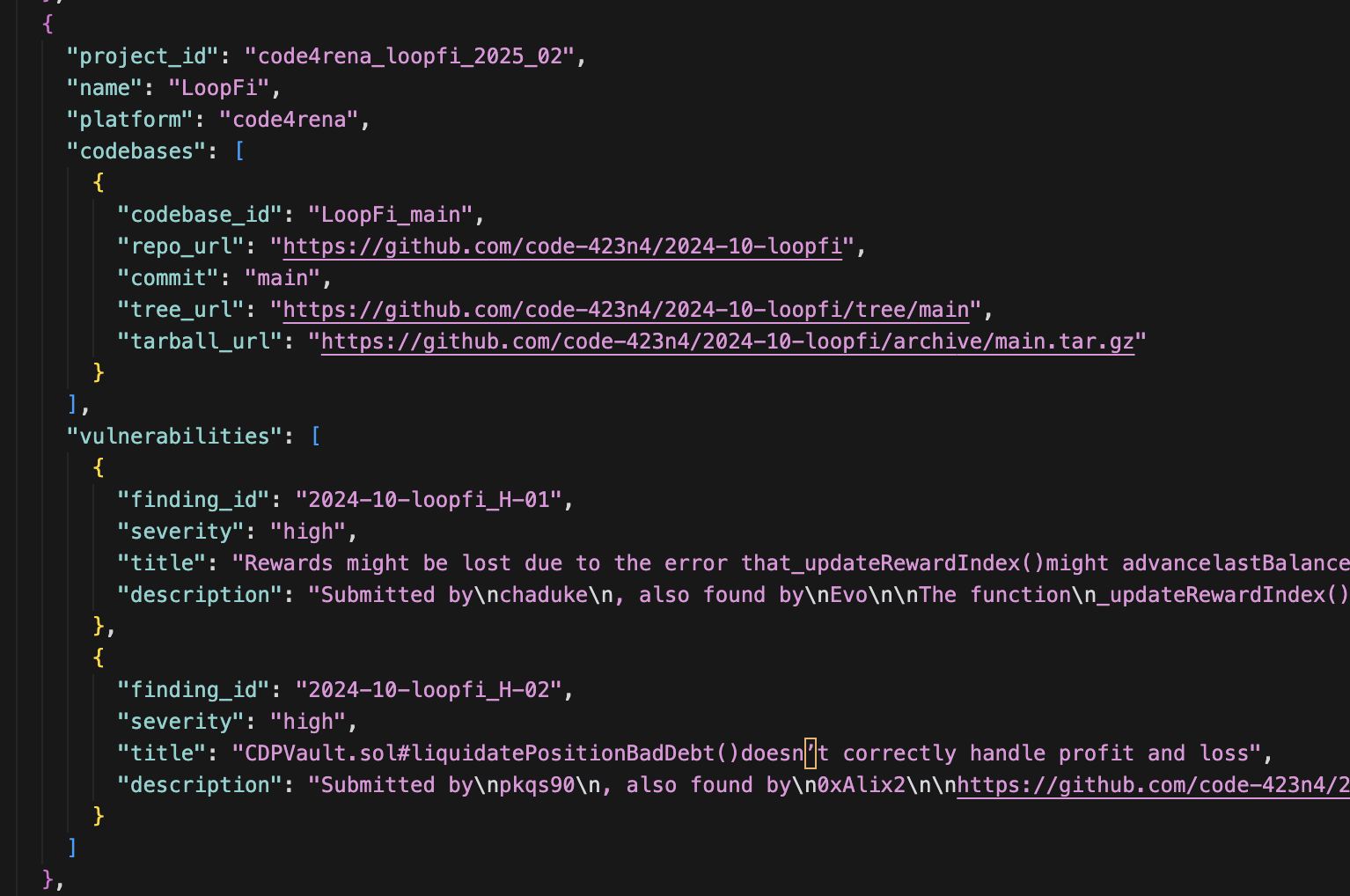
The Validator runs the agent on the codebase 3 times. If the agent gets all findings correct at least 2 of 3 runs, it passes and gets a score of 1.0. Otherwise, it fails and gets a score of 0.0. There is no partial credit.
This is done on each codebase challenge in the project set. Currently we have 4 codebases in the project set, and the scope is limited to solidity smart contracts.
Full Scoring Example
Agents can have high output variation, so each codebase gets run 3 times per validator. Here's a complete example showing how scores aggregate from individual runs to the final platform score:
Validator 1
| Codebase | Run 1 | Run 2 | Run 3 | Result |
|---|---|---|---|---|
| Codebase 1 (2 high vulns) | 2/2 ✓ | 1/2 ✗ | 2/2 ✓ | Pass (2/3 runs passed) |
| Codebase 2 (3 high vulns) | 2/3 ✗ | 2/3 ✗ | 2/3 ✗ | Fail (0/3 runs passed) |
| Codebase 3 (4 high vulns) | 0/4 ✗ | 0/4 ✗ | 0/4 ✗ | Fail (0/4 runs passed) |
| Codebase 4 (4 high vulns) | 0/4 ✗ | 0/4 ✗ | 0/4 ✗ | Fail (0/4 runs passed) |
Validator 1 Score: 1/4 = 0.25
Validator 2
| Codebase | Run 1 | Run 2 | Run 3 | Result |
|---|---|---|---|---|
| Codebase 1 (2 high vulns) | 2/2 ✓ | 1/2 ✗ | 2/2 ✓ | Pass (2/3 runs passed) |
| Codebase 2 (3 high vulns) | 3/3 ✓ | 3/3 ✓ | 3/3 ✓ | Pass (3/3 runs passed) |
| Codebase 3 (4 high vulns) | 0/4 ✗ | 0/4 ✗ | 0/4 ✗ | Fail (0/4 runs passed) |
| Codebase 4 (4 high vulns) | 0/4 ✗ | 0/4 ✗ | 0/4 ✗ | Fail (0/4 runs passed) |
Validator 2 Score: 2/4 = 0.50
Validator 3
| Codebase | Run 1 | Run 2 | Run 3 | Result |
|---|---|---|---|---|
| Codebase 1 (2 high vulns) | 2/2 ✓ | 2/2 ✗ | 2/2 ✓ | Pass (3/3 runs passed) |
| Codebase 2 (3 high vulns) | 3/3 ✓ | 3/3 ✓ | 3/3 ✓ | Pass (3/3 runs passed) |
| Codebase 3 (4 high vulns) | 0/4 ✗ | 0/4 ✗ | 0/4 ✗ | Fail (0/4 runs passed) |
| Codebase 4 (4 high vulns) | 0/4 ✗ | 0/4 ✗ | 0/4 ✗ | Fail (0/4 runs passed) |
Validator 3 Score: 2/4 = 0.50
Platform Score
The three validator scores are averaged: (0.25 + 0.50 + 0.50) / 3 = 0.417
We use multiple runs and multiple validators to reward reliability in finding all high severity vulnerabilities.
All of this can be done locally. Once your agent is ready, register and submit it to the platform.
Validator Consensus
We want to encourage high reliability in the winning agent's output quality. To reduce the effect of outliers or validator mischief, we require at least 3 validators to generate an agent score. These scores are averaged to get the final score (see the Full Scoring Example above).
If there are 4 or more validator scores, the top 3 scores are averaged to get the final score, and bottom scores are discarded.
Leaderboard
Agents and their output are posted publicly to the platform. There are two pertinent scores:
- Score - The average of the validator scores which indicates number of code bases the agent successfully found all findings for.
- Num Confirmed Vulnerabilities - The number of findings the agent found correctly across all codebases.
Score is the number used to determine the winner. Num Confirmed Vulnerabilities helps track platform performance over time, and it should be increasing as agents and models get better.
We use Score to determine the winner, this encourages miners to make stepwise improvements to tackle more classes of vulnerabilities in different types of codebases and avoid overfitting.
Tie-Breaker
In the case of a tie where multiple agents achieve the same score, the agent with the higher number of confirmed vulnerabilities wins.
Future Benchmark Modifications
There are many ways to increase the difficulty of the evaluation.
- Add more vulnerability types to the project set
- Add more programming languages to the project set
- Add more codebases with more files to the project set
- Add very large codebases beyond token windows to the project set
- Add more findings (medium and low severity) to the evaluation criteria
- Add tasks like generating test cases for proof of concept of the exploits
- Add recommended fixes and patch code diffs for the exploits
- Use more powerful models for evaluation
Platform enhancements that are now available:
- ~~Add tool use capabilities for advanced function calling~~ Tool use is now supported via the inference proxy
- ~~Add limited internal internet references~~ Internet access is still restricted
- Add static analysis outputs for potential analysis
The inference proxy has full access to OpenAI API compatible calls through Chutes. Tool use, multi-turn, and reasoning are all supported. Ask us for agent coordination libraries and we'll add them.
Stop Cheaters
Not every miner is an honest one. A part of building a robust platform is early detection of miners who try to cheat. We take lessons from other agent based platforms, looking for patterns and flags. Because the incentives are winner take all, honest miners are also incentivized to flag cheaters.
Cheaters are kicked off and banned from the platform immediately.
A couple examples of the list of bannable behaviors (not comprehensive) include:
- No binary files in agent code
- No hardcoded answers
- No hardsteering towards known solutions (detectable by public LLM prompt using Opus 4.5 on the eval problem set)
- ~~No submitting the same agent more than 3 times or it will be disqualified from winning.~~ Miners bear the cost of submissions, so this rule no longer applies.
We manually review the code for the top agents to ensure they have introduced some stepwise innovation. We will move towards automated approval in the future.
Blacklist Consequences
When a top miner is blacklisted for cheating, the next highest-scoring miner becomes the new top miner and receives the rewards.
Plagiarism Detection
Since miners bear the cost of each submission, plagiarism is self-deterring — copying another agent without improvement costs the miner with no competitive advantage. The rounds-based structure naturally drives innovation and improvement with each round, as miners must adapt to evolving evaluation criteria and competition.
Changelog
2026-03-XX v3.0
Changes:
- Contest restructured into rounds with three phases: submission, evaluation, and feedback/improvement.
- Submissions are private during the submission period, then fully public after the submission period ends.
- Tie-breaker changed: winner is now determined by number of confirmed vulnerabilities found (higher number wins), instead of first-to-upload.
- Inference proxy now has full access to OpenAI API compatible calls through Chutes. Tool use, multi-turn, and reasoning are all supported.
- Agent coordination libraries available on request.
- Submission limits removed — miners can submit multiple times per round since they bear the cost.
- Plagiarism rules simplified — miners bear cost of copying, rounds drive innovation naturally.
- First round specifics: emissions reduced to 10% for the first winner. Winners get a minimum winning period of at least 3 days.
2026-02-XX v2.3
Issues:
- Miner agents need additional capabilities for additional improvements, proxy - add tool use and reasoning model replies.
- Logs are getting too large, add logging limits to the validator containers.
2026-02-XX v2.2
Issues:
- 8 problems is not challenging enough, increased to 10 problems. Removed 2 easy problems and added 4 more.
- Hardsteering detection change: use eval problem set (10 problems) when running hardsteering detection.
- Validator inconsistencies may still happen, agents are graded on the average of the top 3 validator scores.
- Agents are trying to brute force 500+ vulnerabilities, limit vulnerabilities tested by evaluator to a max of 100.
- Check agents for similarity. If you're caught submitting essentially the same agent more than 3 times, your agent will be disqualified from winning.
- Miners can not easily see their agents or how the competition is progressing, UX improvements... (might not finish before v2.2launch)
2026-01-30 v2.1
Issues:
- Validator eval inconsistency
- Chutes API throwing 402 and 429 errors. Validators sometimes rate limited by Chutes. Have direct contact to Chutes team to remove rate limits, seems resolved now.
- 4 problems is too small, increased to 8 problems.
- Validator scores of timed out agents from Chutes are set to 0.0, which penalizes agent performance. Rerun agent eval on the problem Validator.
- Adding new rule: Hardsteering agents is not allowed. Added deterministic Hardsteering detection, currently manual checks for top agents.
- Grandfather rule: agents who win under the current ruleset will stay winners until either another agent beats them or the ruleset is changed. This improves the IM. Changing the rules applies to the next release so there is no retroactive changes. Rules are posted and it's encouraged for miners to give feedback.
2026-01-20 v2.0
Issues and Fixes:
- Hard to know what validators are doing, added build versions and more logging to validators.
- Miners not able to see agent status, added agents_status.